Neo4j > Administration and Maintenance > Availability
High availability features are supported only in the Neo4j enterprise edition which provides the ability to use a master-slave configuration architecture that can be used for availability and horizontal scaling. More than one database server slave can be configured to be the exact replica of the master database server and can be used to make the system continue working in case of hardware failure. The slaves can be also used to handle some of the read load which allows for read scaling.
Using the high availability option is easy, you need just to create the database instance from the HighlyAvailableGraphDatabaseFactory and not from the GraphDatabaseFactory. This mean that there will be no need to change any of the application code if you want to switch to the high available multi machine architecture. Then when your Neo4j server is running in the HA mode, it would expected a single master and zero or more slaves. The new master-slave architecture allows for writes to be served not only from the master instance but also in any of the slaves. The slaves will synchronise the write with the master to maintain consistency. Then after the master receives the new write from the slave, it will propagate the change to all other slaves. This means that in this configuration, the write is eventually consisted and the other slaves can't see the write immediately.
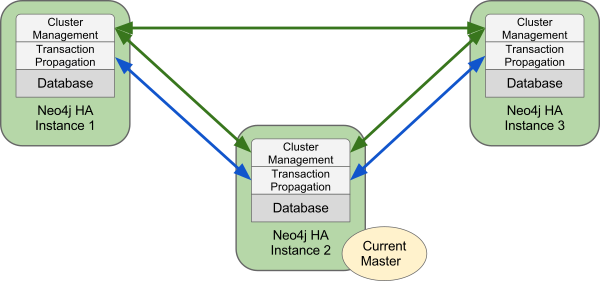
The instances in a HA cluster will monitor each other for availability and monitor if any new instance has joined or any existing instance has left the cluster. They elect a new master automatically when the old one leaves the cluster for any reason. An initial file called ha.initial having a list of urls for the instances inside the cluster, should be provided to any new instance that needs to join the cluster.
To configure the server to use the HA mode, you need to specify the below property in the configuration file conf/neo4j-server.properties:
org.neo4j.server.database.mode=HA
There are many other configuration properties that you can specify while configuring the server to work in the HA mode. For more details about these properties, please see the documentations.
When you do a transaction write, the master will propagate the changes to all the slave after the commit is success. This is done optimistically which means that the transaction will still be successful even if the propagation of the changes to some of the slave fail for some reason. So there is some risk that the transaction will be lost if the changes fail to be pushed to one of the slaves when the master goes down. This means that Transactions are atomic, consistent and durable but transaction will be eventually propagated to all available slaves.
During master failover, a new master will be automatically elected and during this time the writes will be blocked until the new master is available. It is also possible to use arbiter instances which are instances that have only one role which is to participate in election in case there is no odd number of nodes and an instance is needed to break the tie.